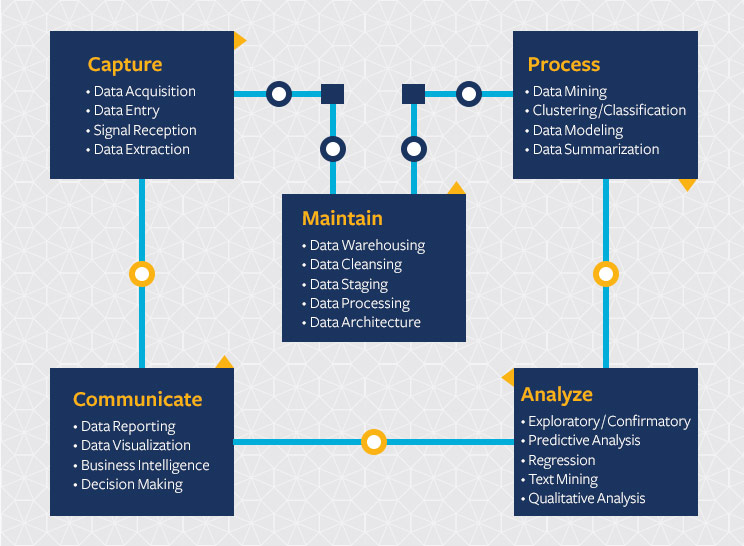
“The ability to take data — to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it — that’s going to be a hugely important skill in the next decades.”
– Hal Varian, chief economist at Google and UC Berkeley professor of information sciences, business, and economics1